Portkey integration
Portkey helps bring Anyscale APIs to production with its abstractions for observability, fallbacks, caching, and more. Use the Anyscale API through Portkey for:
- Enhanced Logging: Track API usage with detailed insights.
- Production Reliability: Automated fallbacks, load balancing, and caching.
- Continuous Improvement: Collect and apply user feedback.
- Enhanced Fine-Tuning: Combine logs and user feedback for targeted fine-tuning.
1.1 Setup and logging
- Set
$ export ANYSCALE_API_KEY=<YOUR_ANYSCALE_ENDPOINT_API_KEY> - Obtain your Portkey API Key.
- Switch to Portkey Gateway URL:
https://api.portkey.ai/v1/proxy
See full logs of requests, like latency, cost, and tokens, and dig deeper into the data with their analytics suite.
- OpenAI Python SDK
- Node.js
- Python
- cURL
""" OPENAI PYTHON SDK """
import openai
PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy"
PORTKEY_HEADERS = {
'Authorization': 'Bearer ANYSCALE_KEY',
'Content-Type': 'application/json',
# **************************************
'x-portkey-api-key': 'PORTKEY_API_KEY', # Get from https://app.portkey.ai/.
'x-portkey-mode': 'proxy anyscale' # Tell Portkey that the request is for Anyscale.
# **************************************
}
client = openai.OpenAI(base_url=PORTKEY_GATEWAY_URL, default_headers=PORTKEY_HEADERS)
response = client.chat.completions.create(
model="mistralai/Mistral-7B-Instruct-v0.1",
messages=[{"role": "user", "content": "Say this is a test"}]
)
print(response.choices[0].message.content)
""" OPENAI NODE SDK """
import OpenAI from 'openai';
const PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy"
const PORTKEY_HEADERS = {
'Authorization': 'Bearer ANYSCALE_KEY',
'Content-Type': 'application/json',
// **************************************
'x-portkey-api-key': 'PORTKEY_API_KEY', // Get from https://app.portkey.ai/.
'x-portkey-mode': 'proxy anyscale' // Tell Portkey that the request is for Anyscale.
// **************************************
}
const openai = new OpenAI({baseURL:PORTKEY_GATEWAY_URL, defaultHeaders:PORTKEY_HEADERS});
async function main() {
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: 'mistralai/Mistral-7B-Instruct-v0.1',
});
console.log(chatCompletion.choices[0].message.content);
}
main();
""" REQUESTS LIBRARY """
import requests
PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy/chat/completions"
PORTKEY_HEADERS = {
'Authorization': 'Bearer ANYSCALE_KEY',
'Content-Type': 'application/json',
# **************************************
'x-portkey-api-key': 'PORTKEY_API_KEY', # Get from https://app.portkey.ai/.
'x-portkey-mode': 'proxy anyscale' # Tell Portkey that the request is for Anyscale.
# **************************************
}
DATA = {
"messages": [{"role": "user", "content": "What happens when you mix red & yellow?"}],
"model": "mistralai/Mistral-7B-Instruct-v0.1"
}
response = requests.post(PORTKEY_GATEWAY_URL, headers=PORTKEY_HEADERS, json=DATA)
print(response.text)
curl "https://api.portkey.ai/v1/proxy/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ANYSCALE_KEY" \
-H "x-portkey-api-key: PORTKEY_API_KEY" \
-H "x-portkey-mode: proxy anyscale" \
-d '{
"model": "meta-llama/Llama-2-70b-chat-hf",
"messages": [{"role": "user", "content": "Say 'Test'."}]
}'
1.2 Enhanced observability
- Trace requests with a single ID.
- Append custom tags for request segmenting and in-depth analysis.
Add their relevant headers to your request:
- OpenAI Python SDK
- Node.js
- Python
- cURL
""" OPENAI PYTHON SDK """
import json
PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy"
TRACE_ID = 'anyscale_portkey_test'
METADATA = {
"_environment": "production",
"_user": "userid123",
"_organisation": "orgid123",
"_prompt": "summarisationPrompt"
}
PORTKEY_HEADERS = {
'Authorization': 'Bearer ANYSCALE_KEY',
'Content-Type': 'application/json',
'x-portkey-api-key': 'PORTKEY_API_KEY',
'x-portkey-mode': 'proxy anyscale',
# **************************************
'x-portkey-trace-id': TRACE_ID, # Send the trace ID.
'x-portkey-metadata': json.dumps(METADATA) # Send the metadata.
# **************************************
}
client = openai.OpenAI(base_url=PORTKEY_GATEWAY_URL, default_headers=PORTKEY_HEADERS)
response = client.chat.completions.create(
model="mistralai/Mistral-7B-Instruct-v0.1",
messages=[{"role": "user", "content": "Say this is a test"}]
)
print(response.choices[0].message.content)
""" OPENAI NODE SDK """
import OpenAI from 'openai';
const PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy"
const TRACE_ID = 'anyscale_portkey_test'
const METADATA = {
"_environment": "production",
"_user": "userid123",
"_organisation": "orgid123",
"_prompt": "summarisationPrompt"
}
const PORTKEY_HEADERS = {
'Authorization': 'Bearer ANYSCALE_KEY',
'Content-Type': 'application/json',
'x-portkey-api-key': 'PORTKEY_API_KEY',
'x-portkey-mode': 'proxy anyscale'
// **************************************
'x-portkey-trace-id': TRACE_ID, // Send the trace ID.
'x-portkey-metadata': JSON.stringify(METADATA) // Send the metadata.
// **************************************
}
const openai = new OpenAI({baseURL:PORTKEY_GATEWAY_URL, defaultHeaders:PORTKEY_HEADERS});
async function main() {
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: 'mistralai/Mistral-7B-Instruct-v0.1',
});
console.log(chatCompletion.choices[0].message.content);
}
main();
""" REQUESTS LIBRARY """
import requests
PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy/chat/completions"
TRACE_ID = 'anyscale_portkey_test'
METADATA = {
"_environment": "production",
"_user": "userid123",
"_organisation": "orgid123",
"_prompt": "summarisationPrompt"
}
PORTKEY_HEADERS = {
'Authorization': 'Bearer ANYSCALE_KEY',
'Content-Type': 'application/json',
'x-portkey-api-key': 'PORTKEY_API_KEY',
'x-portkey-mode': 'proxy anyscale',
# **************************************
'x-portkey-trace-id': TRACE_ID, # Send the trace ID.
'x-portkey-metadata': json.dumps(METADATA) # Send the metadata.
# **************************************
}
DATA = {
"messages": [{"role": "user", "content": "What happens when you mix red & yellow?"}],
"model": "mistralai/Mistral-7B-Instruct-v0.1"
}
response = requests.post(PORTKEY_GATEWAY_URL, headers=PORTKEY_HEADERS, json=DATA)
print(response.text)
curl "https://api.portkey.ai/v1/proxy/chat/completions" \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer ANYSCALE_KEY' \
-H 'x-portkey-api-key: PORTKEY_KEY' \
-H 'x-portkey-mode: proxy anyscale' \
-H 'x-portkey-trace-id: TRACE_ID' \
-H 'x-portkey-metadata: {"_environment": "production","_user": "userid123","_organisation": "orgid123","_prompt": "summarisationPrompt"}' \
-d '{
"model": "meta-llama/Llama-2-70b-chat-hf",
"messages": [{"role": "user", "content": "Say 'Test'."}]
}'
Here’s how the logs appear on your Portkey dashboard:
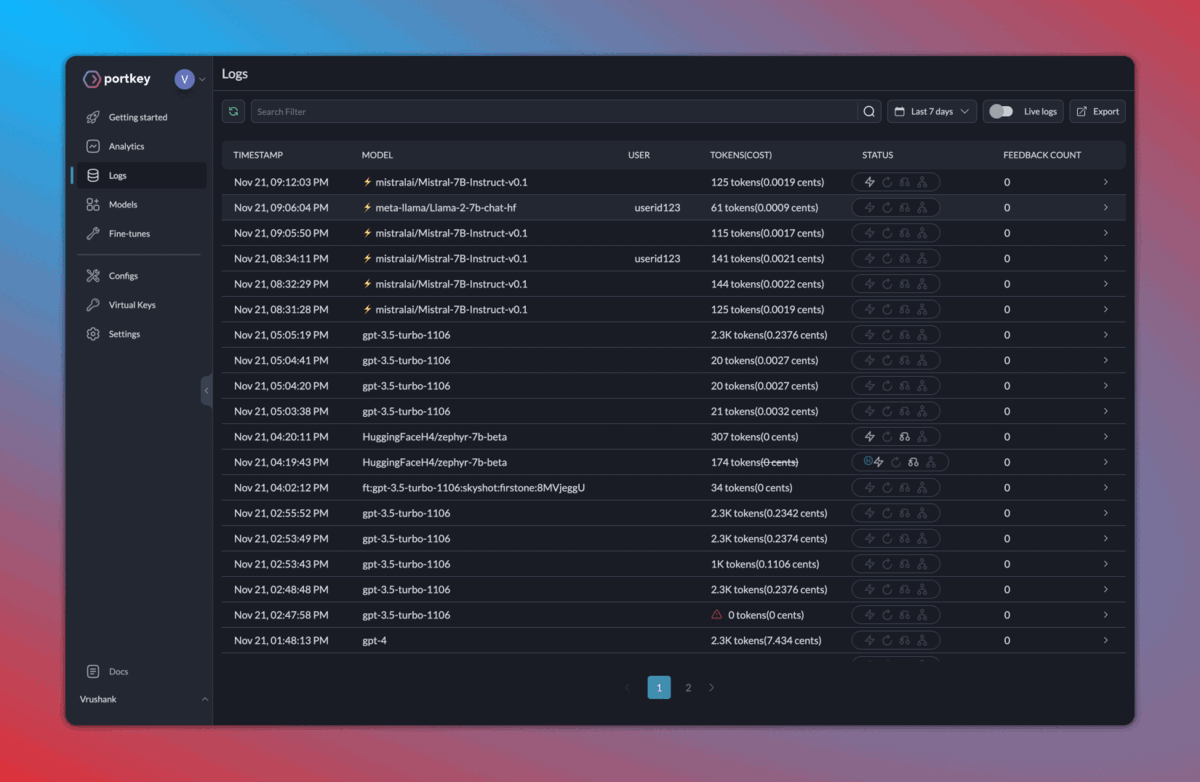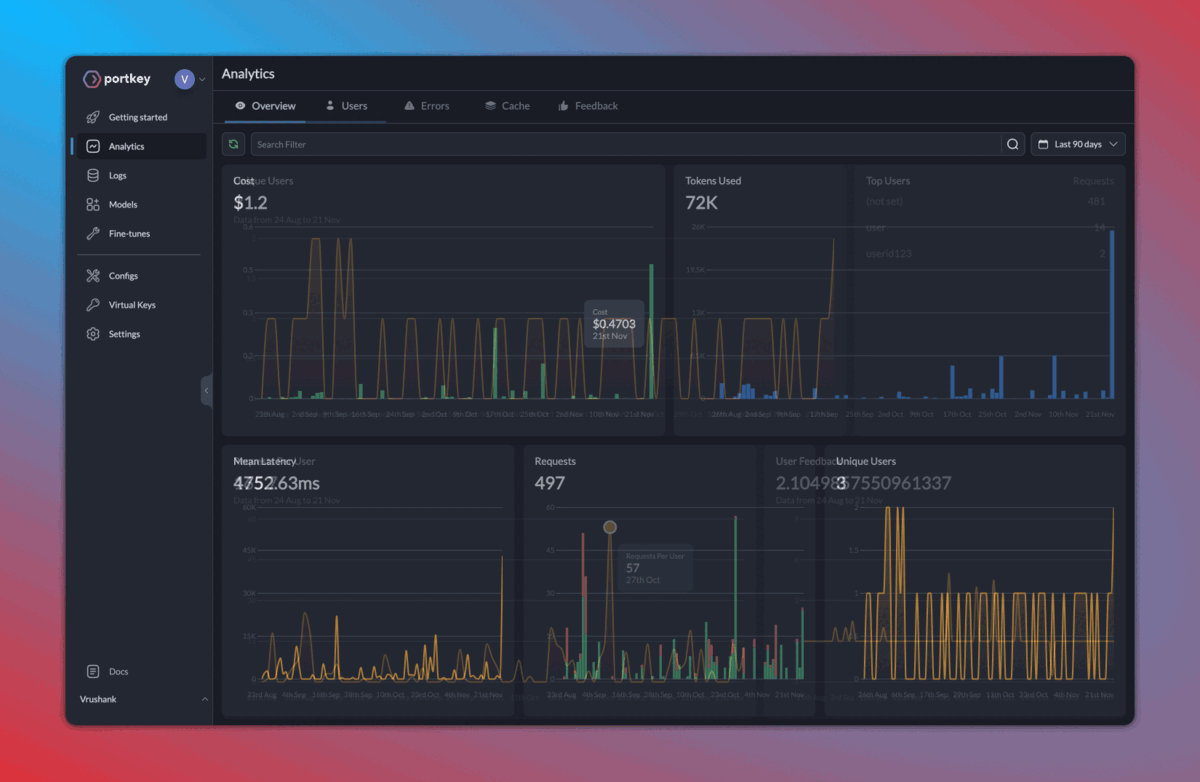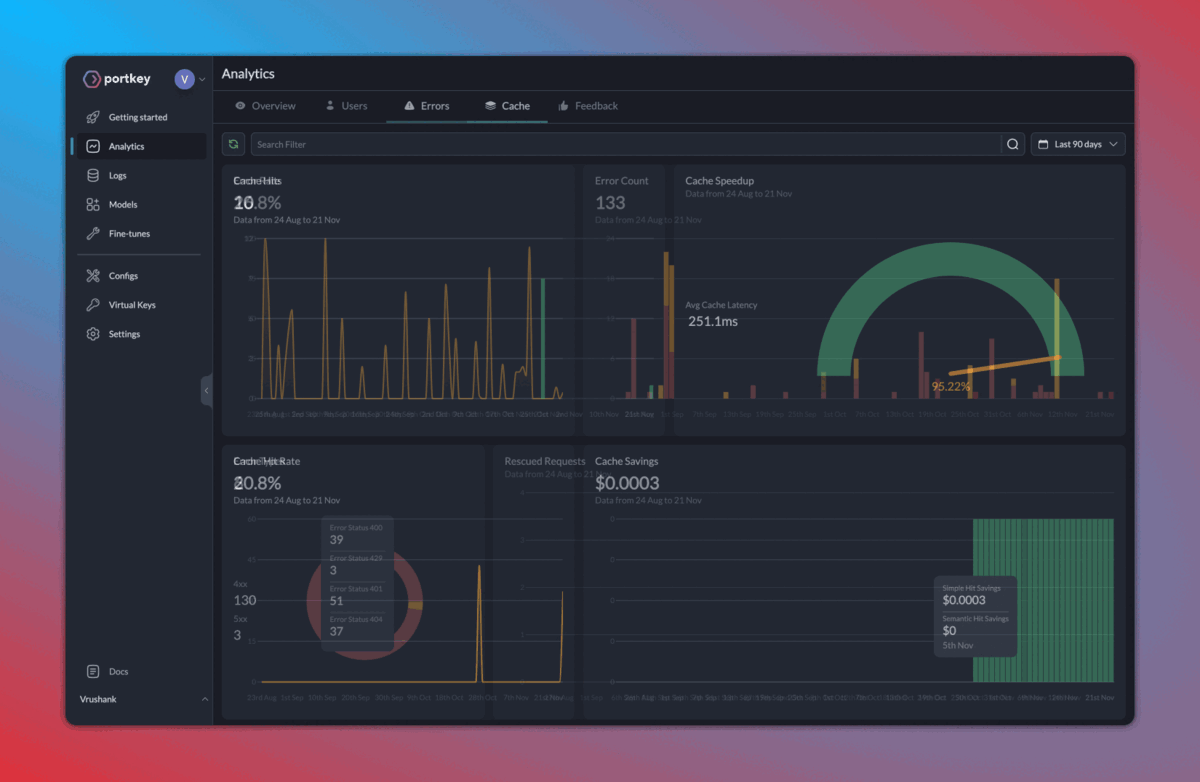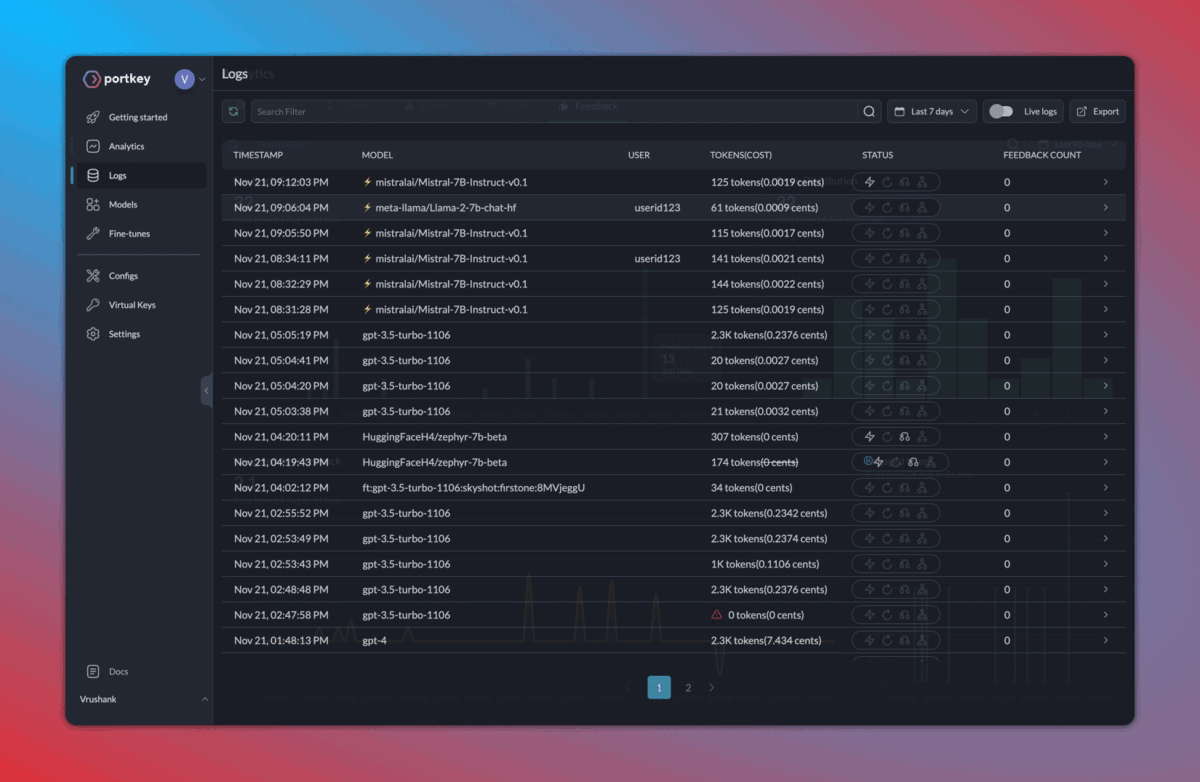
2. Caching, fallbacks, and load balancing
- Fallbacks: Ensure your app remains functional even if a primary service fails.
- Load Balancing: Efficiently distribute incoming requests among multiple models.
- Semantic Caching: Reduce costs and latency by intelligently caching results.
Toggle these features by saving Configs from the Portkey dashboard > Configs tab.
To enable semantic caching and fallback from Llama2 to Mistral, your Portkey config would look like the following:
{
"cache": "semantic",
"mode": "fallback",
"options": [
{
"provider": "anyscale",
"api_key": "...",
"override_params": { "model": "meta-llama/Llama-2-7b-chat-hf" }
},
{
"provider": "anyscale",
"api_key": "...",
"override_params": { "model": "mistralai/Mistral-7B-Instruct-v0.1" }
}
]
}
Next, send the Config key with x-portkey-config header:
- OpenAI Python SDK
- Node.js
- Python
- cURL
""" OPENAI PYTHON SDK """
PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy"
PORTKEY_HEADERS = {
'Content-Type': 'application/json',
'x-portkey-api-key': 'PORTKEY_API_KEY',
'x-portkey-mode': 'proxy anyscale',
# **************************************
'x-portkey-config': 'CONFIG_KEY'
# **************************************
}
client = openai.OpenAI(base_url=PORTKEY_GATEWAY_URL, default_headers=PORTKEY_HEADERS)
response = client.chat.completions.create(
model="mistralai/Mistral-7B-Instruct-v0.1",
messages=[{"role": "user", "content": "Say this is a test"}]
)
print(response.choices[0].message.content)
""" OPENAI NODE SDK """
import OpenAI from 'openai';
const PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy"
const PORTKEY_HEADERS = {
'Content-Type': 'application/json',
'x-portkey-api-key': 'PORTKEY_API_KEY',
'x-portkey-mode': 'proxy anyscale',
// **************************************
'x-portkey-config': 'CONFIG_KEY'
// **************************************
}
const openai = new OpenAI({baseURL:PORTKEY_GATEWAY_URL, defaultHeaders:PORTKEY_HEADERS});
async function main() {
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: 'mistralai/Mistral-7B-Instruct-v0.1',
});
console.log(chatCompletion.choices[0].message.content);
}
main();
""" REQUESTS LIBRARY """
import requests
PORTKEY_GATEWAY_URL = "https://api.portkey.ai/v1/proxy/chat/completions"
PORTKEY_HEADERS = {
'Content-Type': 'application/json',
'x-portkey-api-key': 'PORTKEY_API_KEY',
'x-portkey-mode': 'proxy anyscale',
# **************************************
'x-portkey-config': 'CONFIG_KEY'
# **************************************
}
DATA = {"messages": [{"role": "user", "content": "What happens when you mix red & yellow?"}]}
response = requests.post(PORTKEY_GATEWAY_URL, headers=PORTKEY_HEADERS, json=DATA)
print(response.text)
curl "https://api.portkey.ai/v1/proxy/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ANYSCALE_KEY" \
-H "x-portkey-api-key: PORTKEY_API_KEY" \
-H "x-portkey-mode: proxy anyscale" \
-H "x-portkey-config: CONFIG_KEY" \
-d '{ "messages": [{"role": "user", "content": "Say 'Test'."}] }'
For more on Configs and other gateway features like load balancing, see the Portkey docs.
3. Collect feedback
Gather weighted feedback from users and improve your app:
- Python
- cURL
""" REQUESTS LIBRARY """
import requests
import json
PORTKEY_FEEDBACK_URL = "https://api.portkey.ai/v1/feedback" # Portkey Feedback Endpoint.
PORTKEY_HEADERS = {
"x-portkey-api-key": "PORTKEY_API_KEY",
"Content-Type": "application/json",
}
DATA = {
"trace_id": "anyscale_portkey_test", # On Portkey, you can append feedback to a particular Trace ID.
"value": 1,
"weight": 0.5
}
response = requests.post(PORTKEY_FEEDBACK_URL, headers=PORTKEY_HEADERS, data=json.dumps(DATA))
print(response.text)
curl "https://api.portkey.ai/v1/feedback" \
-H "x-portkey-api-key: PORTKEY_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"trace_id": "anyscale_portkey_test",
"value": 1,
"weight": 0.5
}'
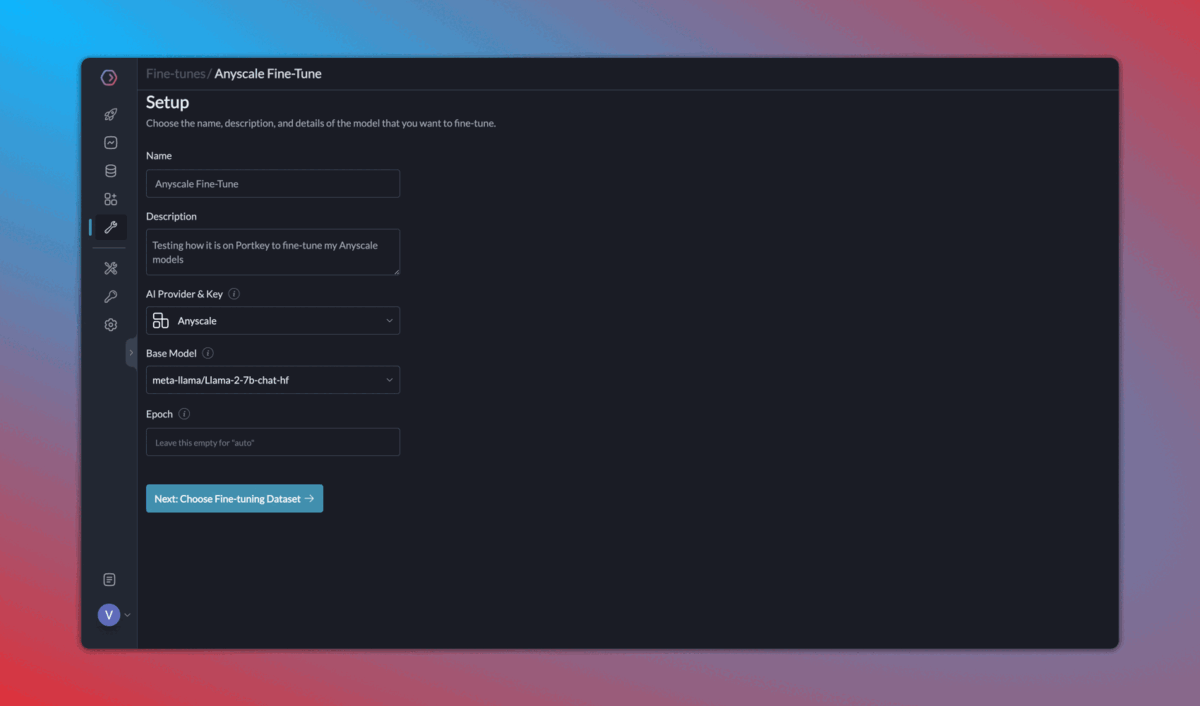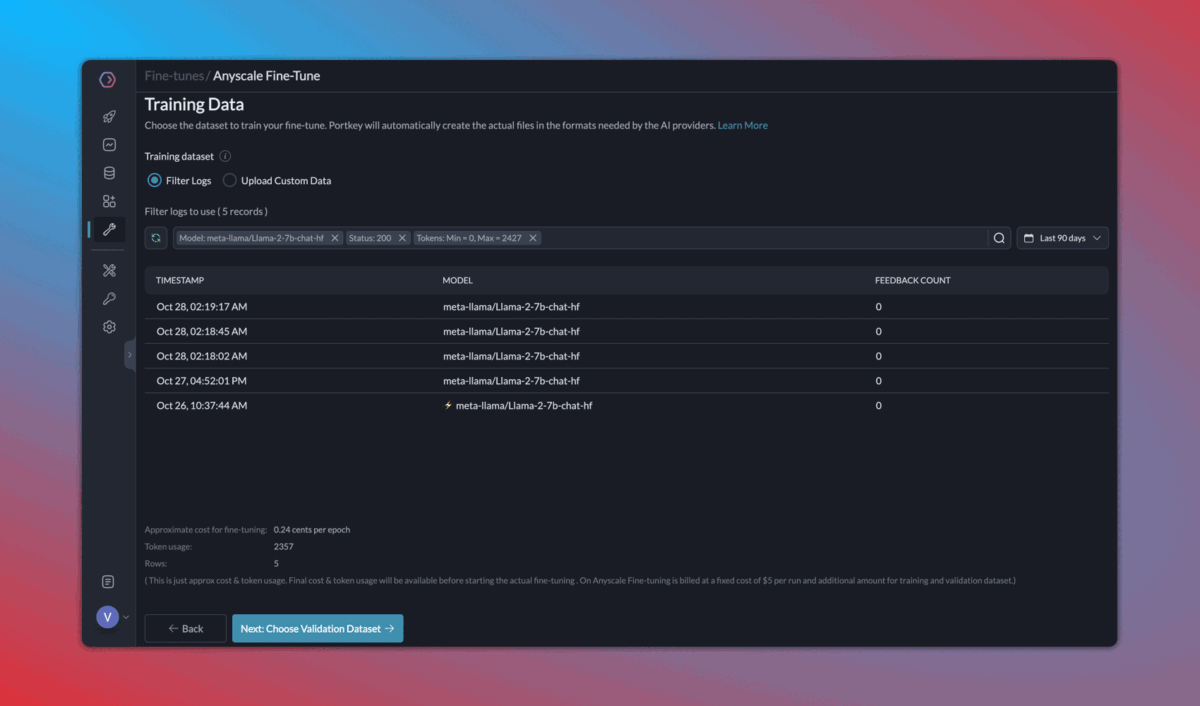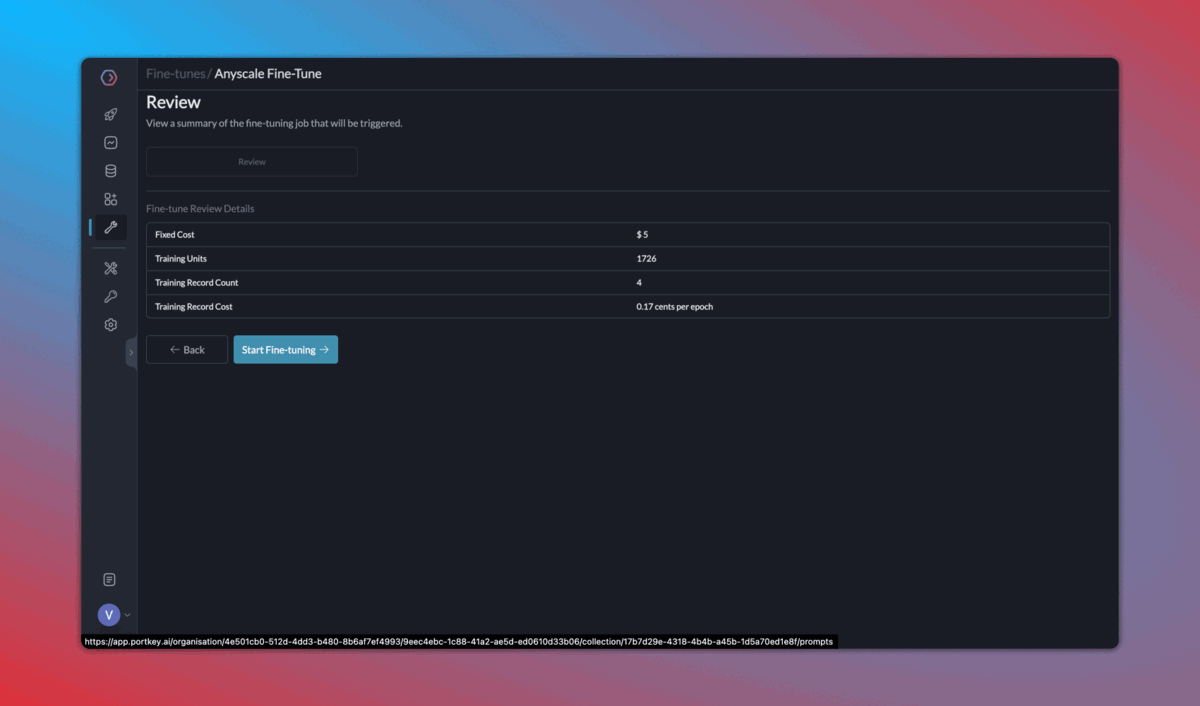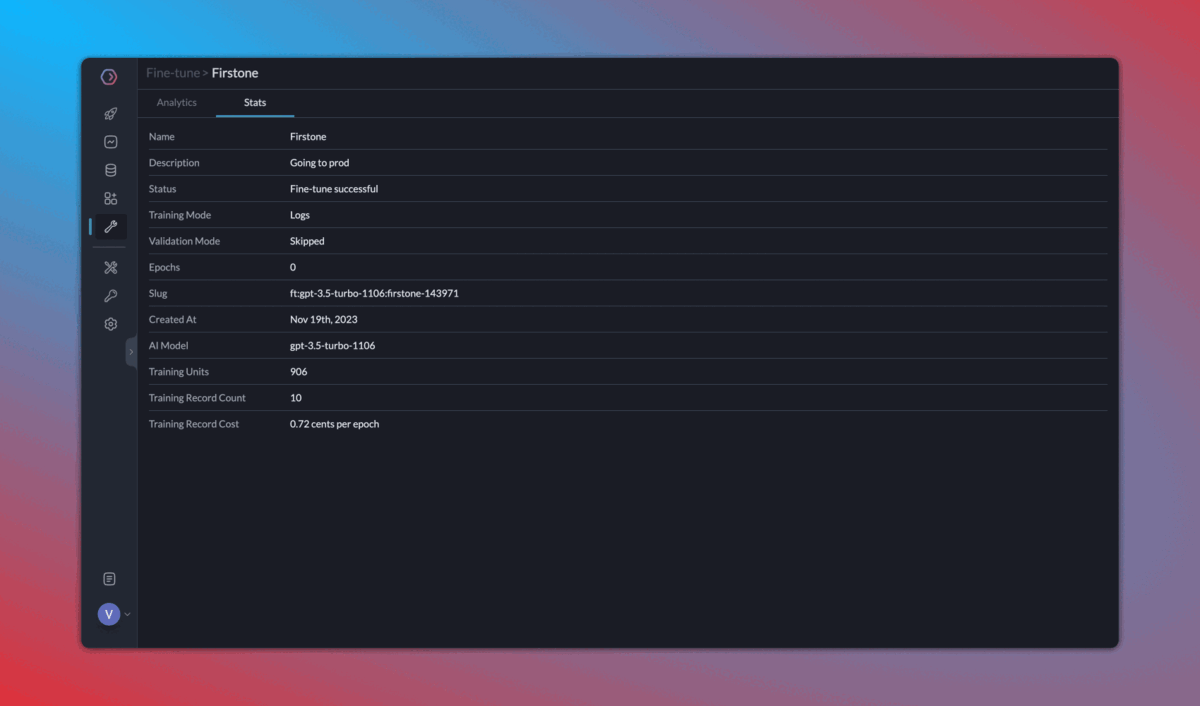
4. Continuous fine tuning
Once you start logging your requests and their feedback with Portkey, it becomes very easy to 1️) Curate & create data for fine-tuning, 2) Schedule fine-tuning jobs, and 3) Use the fine-tuned models.
Fine tuning is enabled for select organizations. Request access on Portkey Discord.
Conclusion
Integrating Portkey with Anyscale helps you build resilient LLM apps. With features like semantic caching, observability, load balancing, feedback, and fallbacks, you can ensure optimal performance and continuous improvement.
Read full Portkey docs here. | Reach out to the Portkey team.